https://d2l.ai/chapter_multilayer-perceptrons/dropout.html?highlight=dropout
4.6. Dropout — Dive into Deep Learning 0.17.1 documentation
d2l.ai
위 링크를 통해 드랍아웃에 대해 정리
종종 학습 데이타의 개수가 적고 네트워크의 파라미터가 너무 많다면
오버피팅 현상이 일어난다.
네트웍이 주어진 테스크 보다 너무 커서 그냥 모조리 외워 버린다랄까.
우리는 네트웍이 지금까지 보지 못한 데이타에 대해서도 잘 수행하기를 원한다.
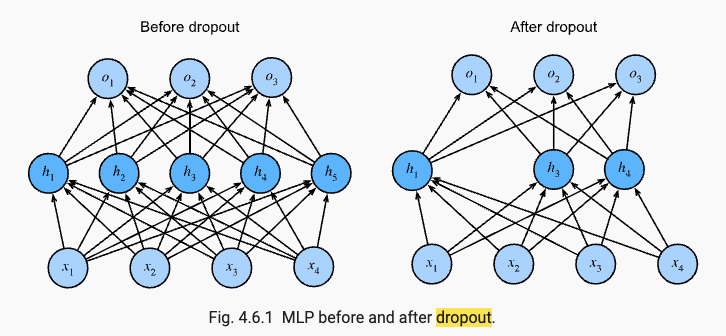
특성(feature)들의 개수가 적은 경우에도, 딥 뉴럴 네트워크는 오버피팅(overfitting) 될 수 있습니다. 뉴럴 네트워크의 뛰어난 유연성을 보여주는 예로, 연구자들은 임의로 레이블(label)l이 할당된 데이터를 완벽하게 분류하는 것을 입증했습니다. 이것이 무엇을 뜻하는지 생각해봅시다. 10개의 분류로 된 레이블들이 균일하게 임의로 부여되어 있는 경우, 어떤 분류기도 10% 이상의 정확도를 얻을 수 없습니다. 이렇게 패턴을 학습할 수 없는 경우에도, 뉴럴 네트워크는 학습 레이블들에 완벽하게 맞춰질 수 있습니다.
Randomly Drop Nodes
Dropout is a regularization method that approximates training a large number of neural networks with different architectures in parallel.
During training, some number of layer outputs are randomly ignored or “dropped out.” This has the effect of making the layer look-like and be treated-like a layer with a different number of nodes and connectivity to the prior layer. In effect, each update to a layer during training is performed with a different “view” of the configured layer.
By dropping a unit out, we mean temporarily removing it from the network, along with all its incoming and outgoing connections
— Dropout: A Simple Way to Prevent Neural Networks from Overfitting, 2014.
Dropout has the effect of making the training process noisy, forcing nodes within a layer to probabilistically take on more or less responsibility for the inputs.
This conceptualization suggests that perhaps dropout breaks-up situations where network layers co-adapt to correct mistakes from prior layers, in turn making the model more robust.
… units may change in a way that they fix up the mistakes of the other units. This may lead to complex co-adaptations. This in turn leads to overfitting because these co-adaptations do not generalize to unseen data. […]
— Dropout: A Simple Way to Prevent Neural Networks from Overfitting, 2014.
Dropout simulates a sparse activation from a given layer, which interestingly, in turn, encourages the network to actually learn a sparse representation as a side-effect. As such, it may be used as an alternative to activity regularization for encouraging sparse representations in autoencoder models.
We found that as a side-effect of doing dropout, the activations of the hidden units become sparse, even when no sparsity inducing regularizers are present.
— Dropout: A Simple Way to Prevent Neural Networks from Overfitting, 2014.
Because the outputs of a layer under dropout are randomly subsampled, it has the effect of reducing the capacity or thinning the network during training. As such, a wider network, e.g. more nodes, may be required when using dropout.
내가 이해한 것을 조금 쉽게 설명 해보자면
드랍아웃은 주어진 테스크에 따라 사용 유무를 결정해야 할 것 같다.
주어진 표지판이 있을때 어떤 표지판인지 판별하는 네트워크를 구성한다 가정해보자.
표지판 데이타를 학습시켰다.
테스트 데이타를 통해 검증을 하는데 정확도가 낮다.
이유는 테스트 데이타에는 표지판의 일부가 가려져 있기 때문이다.
네트웍은 완벽한 표지판이 주어졌을때만 정확한 판단을 한다.
이런,, 우리는 일부 노이즈가 들어간 (표지판 일부가 가려진) 표지판도 판별하도록 학습시키고 싶은데 어쩌지?
이럴때 드랍아웃이 유용하다고 생각된다.
표지판의 일부을 랜덤으로 가려가면서 학습을 진행하게 된다면
테스트에서 나오는 노이즈 섞인 표지판도 잘 판별하지 않을까?
'딥러닝 공부' 카테고리의 다른 글
| vocabulary and tokenizer (0) | 2022.01.07 |
|---|---|
| what is beam search? (0) | 2022.01.07 |
